MEND RenovateとBoltをやる(旧WhiteSourceのGitHubApp)
やります。
Renovateやる。
ドキュメント https://docs.renovatebot.com/
GitHubのMarket placeからRenovateを検索して set up a plan を選択。
画面遷移するので install it for free を選択。

アカウントを選択してインストール。

インストールするリポジトリを選択。Allにすると初期セットアップの Pull Request がすべてのリポジトリに作成されてしまう。基本はOnly selectで良いと思う。

インストールするとRenovate Dashboardなるものが現れる。Sign in with GitHubを選択してみる。

Authorizeする。

Mend Renovate Registrationをする。Companyは空にした。

Dash Board が表示される。中身はまだない。

リポジトリにはRenovate設定のためのPull Request が作成される。

中身はこんな感じ。What to Expect に書かれたPRが作成されると言っている。ひとまずマージする。

renovate.jsonが作成される。

Renovate の設定項目は大量なので、よく使う設定をまとめて共有する手段としてプリセットという仕組みが用意されているらしい。
- 設定項目:https://docs.renovatebot.com/configuration-options/
- プリセット:https://docs.renovatebot.com/config-presets/
デフォルトで書かれた「config:base」は、下記の設定を一つにまとめたプリセットらしい。
{
"extends": [
":dependencyDashboard",
":semanticPrefixFixDepsChoreOthers",
":ignoreModulesAndTests",
":autodetectPinVersions",
":prHourlyLimit2",
":prConcurrentLimit20",
"group:monorepos",
"group:recommended",
"workarounds:all"
]
}
設定はそうとうな量があるっぽいのでここでは省略する。はい。
で、Issueを見るとDependency Dashboardなるものがある。

Dependency Dashboard は Renovate の方で判断してくれた、「バージョンアップしたほうが良い情報」を提示してくれ、かつ Pull Request も作成してくれるインターフェースをもつお助けツールらしい。 無効化している人が多そうなのでそうする。
{
"$schema": "https://docs.renovatebot.com/renovate-schema.json",
"extends": [
"config:base"
],
"dependencyDashboard": false //追加
}
pushするとDependency DashboardのIssueは勝手にクローズされた。
ちなみにRenovate Dashboard(Dependencyじゃないよ)は以下のような感じ。Jobのログが出るのだね。あまり見ることはなさそう?


ひとまずマージしてみよう。
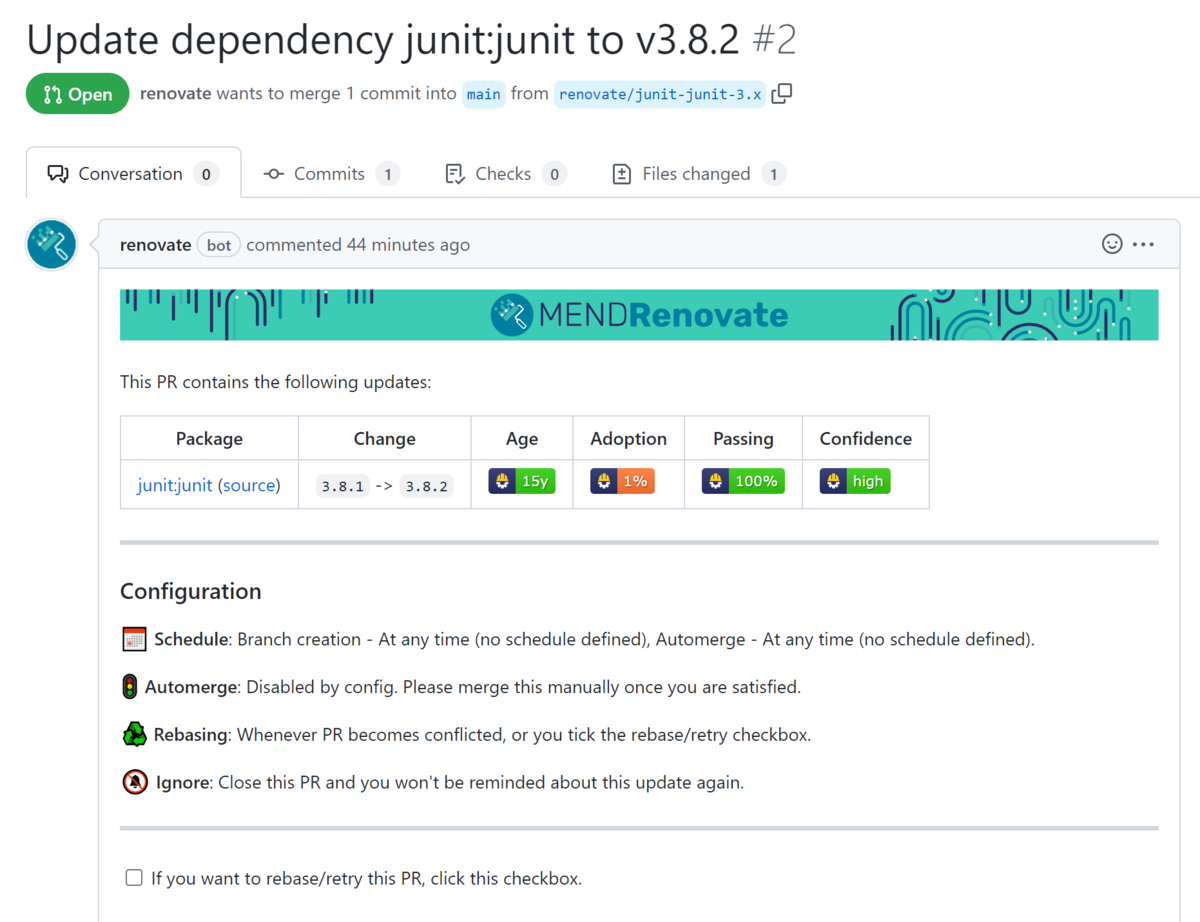
なにやらAge, Adoption とかのアイコンが気になる。これはMerge Confidence(日本語だとマージ信頼度か?)というものらしい。 https://docs.renovatebot.com/merge-confidence/
- Age: パッケージの年齢
- Adoption: このリリースを使用している該当パッケージのユーザー (Renovate内) の割合
- Passing: このパッケージのテストに合格したアップデートの割合
- Confidence: この更新の信頼度
ちなみに本データはnpm, Maven, PyPIしか(現状は)サポートされていない。
ひとまず全部プルリクをマージしておいた。
脆弱性アラート
Renovateはデフォルトで脆弱性が出た場合にプルリクを投げるらしい。GitHubのVulnerability Alertsを読み込んで、Pull Requestsをカスタマイズできるっぽい。 https://docs.renovatebot.com/configuration-options/#vulnerabilityalerts
GitHubのDependency graphとDependabot alertsを有効にする必要がある。こんな感じ。

ここにも書いてあったが、Dependabot alertsはWhiteSourceのデータなども基にしているよう。RenovateだけがWhiteSourceのデータを持っていてそこが差別化ポイントなのかと思っていたがそうではないらしい。情報源としてはDependabotもRenovateも変わらん。
Renovateの結論
- Dependabotの設定をより柔軟にできるのがRenovate(多分)
- 情報源はDependabotもRenovateも変わらない(多分)
メモ:npmの管理はこの辺りが参考になりそうだった。
https://zenn.dev/kjirou/articles/1df0795ad3bfde
Boltやる
Boltのドキュメントはこれらしい。 https://docs.mend.io/bundle/community_tools/page/mend_bolt_for_github.html
Renovateと同じようにMarket placeからインストールする。 なおサポート言語はC, C#, C++, Go, Java, JavaScript, Objective-C, PHP, Python, Rubyらしい。 あと各リポジトリで1日あたりスキャン×5回しかできないらしい。
とりまインストール。

こちらもリポジトリを選択する。

Authorizeする。

こちらもレジストレーション。

サクセス。

指定したリポジトリにプルリクが来ている。

Renovateと同じくオンボーディングpullreq。とりあえずマージする。

.whitesourceファイルが追加される。

少し待つとIssueが出てきた。

まずexpress。19の脆弱性が見つかっている。この中にexpressの脆弱性はない。なぜならバージョンアップしたことでexpress自体の脆弱性はすでになくなっているから。ここで出た19件はexpressに依存しているパッケージの脆弱性になる。

注目点としては、「WS」から始まっている脆弱性があること。WhiteSourceが発行した(CVEではない)ものである。
あと気になった点は、Dependabot alertが18件なのに対し、こちらは19件出ていること。

差分を調べると以下のような具合だった。
- 両者とも17件はまったく同じ脆弱性(CVE)
- 1件はbase64-urlの脆弱性で、これは名称違いで両方とも検出された。どうもCVEで採番されていないものらしい。
- Dependabot:GHSA-j4mr-9xw3-c9jx base64-url
- Bolt:WS-2018-0111 detected in multiple dependencies
- 最後の1件がqsの脆弱性。Boltでのみ検出された。
- WS-2014-0005 qs-0.6.6.tgz
リンクの中身を見てもちょっと分からない。 そしてqsは同じバージョンで脆弱性が出ていたので、そちらとの重複かもしれない。よって検出内容としてはDependabot alertもBoltも変わらない気がする。
で、面白そうなのはRemediation Available。これが現状はすべて×になっている。これを有効化すると自動でpullreqを作ってくれるのではないだろうか。どうやるのか分からんけど。

ふと、ドキュメントを見てみると以下の文言が。 https://docs.mend.io/bundle/community_tools/page/mend_bolt_for_github.html#Initiating-a-Scan
Mend のスキャンは、有効な GitHub のプッシュコマンドによって開始されます。有効なプッシュコマンドは、以下の要件のうち少なくとも一つを満たしています。 - プッシュコマンドのいずれかのコミットが、mendがサポートする拡張子を持つソースファイルを追加/削除している。特定の言語とその拡張子がサポートされているかどうかを調べるには、Mend Languages ページを参照してください。 - push コマンドのコミットのひとつに、パッケージマネージャの依存ファイルの追加/変更が含まれています。サポートされている依存ファイルのリストを参照し、あなたの依存ファイルがサポートされているかどうかを調べてください。
パッケージマネージャしか見ないと思ってたが…。試しにjquery-2.2.2のファイルを追加してpushしてみよう。

一瞬でIssue出てきたw

すごい。ということはBoltは依存関係だけではなくてソースもスキャンしてOSSを検出しているということになる。ほう。 誤検知があり得ると思うので一長一短あると思うが。これ無効化することってできないのかな。
.whitesourceの設定は以下のような感じ。
{
"scanSettings": {
"baseBranches": []
},
"checkRunSettings": {
"vulnerableCheckRunConclusionLevel": "failure",
"displayMode": "diff",
"useMendCheckNames": true
},
"issueSettings": {
"minSeverityLevel": "LOW",
"issueType": "DEPENDENCY"
}
}
パラメータの説明はここに書かれているが、オプション×2つのことしか書かれていない。他はどこに書かれてるんだこれ。 https://docs.mend.io/bundle/community_tools/page/mend_bolt_for_github.html#Parameters
- vulnerableCheckRunConclusionLevel (success or failure):Boltが脆弱性を検出したときのステータスをsuccessにするかfailureにするか。failureにするとGitHub Checksで死んでくれる。
- minSeverityLevel (NONE or LOW or MEDIUM or HIGH):Issueを作成する最低ライン。デフォルトはLOW。NONEにするとIssueが作られない。
GitHub Checks API統合ができるのでやってみよう。プライベートリポジトリではダメなのでパブリックリポジトリで試す必要がある。
まずは Settings > Branches > Add branch protection rule

- 対象ブランチに「*」を入力
- Require status checks to pass before merging を選択
- Select で Mend Security Check をチェック

CodeタブにChecks API Indicators(×印だと思う)が表示される。これを選択するとポップアップが表示される。checksの結果が表示される。

ポップアップのDetailsを選択すると詳細が表示される。

それではプルリクを作ってみる。作ってみたが、なかなか進まない。

Checksタブも。

本来はプルリクのページがこんな感じになるっぽい。

でChecksがこんな?

うむ。ドキュメントに書いてあるのはこんなものですね。
はい
とりあえず動作確認をおこなった。機能的にBoltは最低限という感じだろうか。
有償版?には結構いろいろ設定があるので、色々できそう。ライセンスチェックとかRenovate連携とかができそうな感じだった。 https://docs.mend.io/bundle/integrations/page/mend_for_github_com.html
以上
GitHub Actions self hosted runnerをやる
やります。
環境作り
GitHubのリポジトリSettings > Actions > Runners > New self-hosted runner を選択。

WSL2のUbuntuに入れるのでLinuxを選択。基本は指示にしたがって構築していく。

# Create a folder $ mkdir actions-runner && cd actions-runner # Download the latest runner package $ curl -o actions-runner-linux-x64-2.295.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.295.0/actions-runner-linux-x64-2.295.0.tar.gz # Optional: Validate the hash $ echo "a80c1ab58be3cd4920ac2e51948723af33c2248b434a8a20bd9b3891ca4000b6 actions-runner-linux-x64-2.295.0.tar.gz" | shasum -a 256 -c # Extract the installer $ tar xzf ./actions-runner-linux-x64-2.295.0.tar.gz
config.shはすべてデフォルト設定とした。
$ ./config.sh --url https://github.com/xxx/yyy --token ****************** -------------------------------------------------------------------------------- | ____ _ _ _ _ _ _ _ _ | | / ___(_) |_| | | |_ _| |__ / \ ___| |_(_) ___ _ __ ___ | | | | _| | __| |_| | | | | '_ \ / _ \ / __| __| |/ _ \| '_ \/ __| | | | |_| | | |_| _ | |_| | |_) | / ___ \ (__| |_| | (_) | | | \__ \ | | \____|_|\__|_| |_|\__,_|_.__/ /_/ \_\___|\__|_|\___/|_| |_|___/ | | | | Self-hosted runner registration | | | -------------------------------------------------------------------------------- # Authentication √ Connected to GitHub # Runner Registration Enter the name of the runner group to add this runner to: [press Enter for Default] Enter the name of runner: [press Enter for DESKTOP-*******] This runner will have the following labels: 'self-hosted', 'Linux', 'X64' Enter any additional labels (ex. label-1,label-2): [press Enter to skip] √ Runner successfully added √ Runner connection is good # Runner settings Enter name of work folder: [press Enter for _work] √ Settings Saved.
runする。
$ ./run.sh √ Connected to GitHub Current runner version: '2.295.0' 2022-08-20 04:25:51Z: Listening for Jobs
これでRunnersに追加される。

一度runを終了するとstatusがofflineになる。

とりあえずlsしてみる。
$ pwd /home/<username>/actions-runner $ ls _diag config.sh run-helper.cmd.template run.sh actions-runner-linux-x64-2.295.0.tar.gz env.sh run-helper.sh safe_sleep.sh bin externals run-helper.sh.template svc.sh
GitHub側でいったんRunnerをRemoveしてみる。

こんな画面が出てくる。どうもコマンドで削除した方が良いらしい。

画面に出てきたコマンドを投入。
./config.sh remove --token ********************* # Runner removal √ Runner removed successfully √ Removed .credentials √ Removed .runner $ ls _diag config.sh run-helper.cmd.template run.sh actions-runner-linux-x64-2.295.0.tar.gz env.sh run-helper.sh safe_sleep.sh bin externals run-helper.sh.template svc.sh
なんか見た目は変わっていない。.runnerとかの隠しフォルダが消えたのかな。
試しにrunしてみる。予定通りエラーとなる。
$ ./run.sh An error occurred: Not configured. Run config.(sh/cmd) to configure the runner. Runner listener exit with terminated error, stop the service, no retry needed. Exiting runner...
GitHub側も消えている。
一度全消しして世界をもう一度始めよう。
$ mkdir actions-runner && cd actions-runner $ ls -a $ curl -o actions-runner-linux-x64-2.295.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.295.0/actions-runner-linux-x64-2.295.0.tar.gz $ ls actions-runner-linux-x64-2.295.0.tar.gz $ tar xzf ./actions-runner-linux-x64-2.295.0.tar.gz $ ls -a . actions-runner-linux-x64-2.295.0.tar.gz config.sh externals run-helper.sh.template safe_sleep.sh .. bin env.sh run-helper.cmd.template run.sh $ ./config.sh --url https://github.com/xxxx/yyyy --token ***************** (省略)//全部デフォルト $ ls -a . .env actions-runner-linux-x64-2.295.0.tar.gz externals safe_sleep.sh .. .path bin run-helper.cmd.template svc.sh .credentials .runner config.sh run-helper.sh.template .credentials_rsaparams _diag env.sh run.sh
config.shを叩くと svc.sh や隠しファイルが出力される。
そしてGitHub側でRunnerが出てくる。
とりあえずrunを叩く。
$ ./run.sh √ Connected to GitHub Current runner version: '2.295.0' 2022-08-20 05:01:15Z: Listening for Jobs
この状態で動くか確認する。.github/workflows の yml の runs-on を self-hosted に変更してpush。
#runs-on: ubuntu-latest
runs-on: self-hosted
無事動作した。
$ ls _diag bin externals run-helper.sh.template svc.sh _work config.sh run-helper.cmd.template run.sh actions-runner-linux-x64-2.295.0.tar.gz env.sh run-helper.sh safe_sleep.sh
サービス化
サービス化する場合はsvc.shを用いる。config.sh
coming soon
ssh関連のメモ
GitHubにSSH接続とかするのでそれ関連のメモです。 (いいかげんメモろう)
公開鍵と秘密鍵のペアを作成
鍵のペアをRSA暗号化方式、4096ビットで生成する。
$ ssh-keygen -t rsa -b 4096 -C "メールアドレス" Generating public/private rsa key pair. Enter file in which to save the key (/home/dmorishita/.ssh/id_rsa): /home/<username>/.ssh/id_rsa_github Enter passphrase (empty for no passphrase): //入力 Enter same passphrase again: //入力 Your identification has been saved in /home/<username>/.ssh/id_rsa_github Your public key has been saved in /home/<username>/.ssh/id_rsa_github.pub The key fingerprint is: (省略)
秘密鍵と公開鍵が作成される。(消すときは本ファイルを消せばおK)
$ ls ~/.ssh id_rsa_github id_rsa_github.pub
毎回パスフレーズを入力しなくていいよう、ssh agent(認証鍵を保存するプログラム)に鍵を追加しておく。
ssh-agentを起動する。
$ eval `ssh-agent` Agent pid 131 $ ps xf | grep ssh-agent //動作確認 131 ? Ss 0:00 ssh-agent $ ssh-add -l //何も保存されていない確認 The agent has no identities.
鍵を追加する。
$ ssh-add ~/.ssh/id_rsa_github Enter passphrase for /home/<username>/.ssh/id_rsa_github: Identity added: /home/<username>/.ssh/id_rsa_github (xxxx@gmail.com) $ ssh-add -l //確認 4096 SHA256:********************* xxxx@gmail.com (RSA)
※参考:ssh-agentを止めるとき
$ ssh-agent -k unset SSH_AUTH_SOCK; unset SSH_AGENT_PID; echo Agent pid 131 killed;
GitHub の settings > SSH and GPG keys > New SSH key で公開鍵(.pub)の内容を張り付ける。Titleは適当。

動作確認する。最初はknown_hostsに追加するか聞かれる。
$ ssh -T git@github.com Are you sure you want to continue connecting (yes/no/[fingerprint])? yes //入力 Hi <username>! You've successfully authenticated, but GitHub does not provide shell access. $ ls .ssh //known_hostsができる id_rsa_github id_rsa_github.pub known_hosts
※参考:鍵の更新などがあった場合には ssh-keygen -R にて削除する。
$ ssh-keygen -R github.com # Host github.com found: line 1 /home/<username>/.ssh/known_hosts updated. Original contents retained as /home/<username>/.ssh/known_hosts.old $ ls .ssh id_rsa_github id_rsa_github.pub known_hosts known_hosts.old
git clone する
$ git clone git@github.com:square/okhttp.git Cloning into 'okhttp'... remote: Enumerating objects: 129913, done. remote: Counting objects: 100% (83/83), done. remote: Compressing objects: 100% (54/54), done. remote: Total 129913 (delta 20), reused 63 (delta 13), pack-reused 129830 Receiving objects: 100% (129913/129913), 46.51 MiB | 7.86 MiB/s, done. Resolving deltas: 100% (64548/64548), done.
セキュリティ投資の費用対効果はどうやって出すのか論
メモ
ユニシスさんのやつ

リスク定量化手法のALE(Annual Loss Expectation)とかが書いてある。
https://www.unisys.co.jp/tec_info/tr86/8606.pdf
経営層と議論するためのサイバーリスクの数値化モデル
いろいろ書いてある。
https://www.pwc.com/jp/ja/knowledge/prmagazine/value-navi201902/cyber-risk.html
システム開発の「後工程になるほどコストかかる」の情報調べ
IT系の人間であれば「後工程ほどバグ修正にコストがかかる」という話は当たり前のように知っていますよね。
今回はこれについてエビデンス?というか、実際誰がどんなこと言ってるのか調べる必要があったので、メモ用に記事として残しておこうと思います。
Barry Boehm “Software Engineering Economics” (Prentice Hall, 1981)

https://www.itmedia.co.jp/im/articles/0402/21/news003.html
http://mot2007.sakura.ne.jp/Project_Management/PM0112.htm
B. Boehm and V. Basili “Software Defect Reduction Top 10 List” , IEEE Computer

JASPIC SPIJapan2009 奈良隆正「ソフトウェア品質保証の方法論、技法、その変遷

http://www.jaspic.org/event/2014/SPIJapan/session1A/1A3_ID008.pdf
How Google Tests Software

https://monoist.itmedia.co.jp/mn/articles/2109/21/news001_3.html
https://www.youtube.com/watch?v=ajXSunT9kus
Parasoft Japan社長

https://codezine.jp/devsumi/2008/test/report/04/
國友義久:効果的プログラム開発技法 , 近代科学社 , (1988)

https://www.intec.co.jp/company/itj/itj18/contents/itj18_10-17.pdf
The Economic Impacts of Inadequate Infrastructure for Software Testing (NIST)


https://www.nist.gov/system/files/documents/director/planning/report02-3.pdf
Applied Software Measurement (Capers Jones)

https://www.techmatrix.co.jp/t/quality/
IBM System Science Institute Relative Cost of Fixing Defects

https://www.synopsys.com/blogs/software-security/ja-jp/cost-to-fix-bugs-during-each-sdlc-phase/
C/C++のパッケージマネージャについて簡単に調べたのでメモ
クロスコンパイルな組み込みのプロジェクトで使われてるパッケージマネージャってなんなんでしょう。 自分C/C++はまったく触ってこなかった人なのでさっぱりなのです。
とりあえずここに載っていたものを見てみようと思う。
C++ パッケージマネージャ - C++ の歩き方 | cppmap
Vcpkg
https://github.com/Microsoft/vcpkg
CMakeベースのパッケージ管理システム。読み方が分からない。
OpenCVを取得する例: https://qiita.com/UnaNancyOwen/items/54c6334f269d03646cad
ぱっと見た感じ、ソースを取得してCMakeをゴニョゴニョしてビルドして、必要なパッケージそろえますって人に見える。
Conan
https://github.com/conan-io/conan
一番知っている。JFrogがやってるんだね。
Hunter
情報が全然ないのでスルーします。ごめんなさい。
Buckaroo
https://github.com/LoopPerfect/buckaroo
非中央集権なパッケージマネージャ。パッケージレジストリを持たず、GitHub/GitLab/Bitbucketなどから直接依存関係を取得するっぽい。
poac
ぽっく。国産。立命館大学の学生が開発。
これがレジストリ?→ https://poac.pm/
全然パッケージがないけど。
https://github.com/poacpm/poac
2021年2月時点で「開発中であり使い物にならない」と作者が言っている。
めっっっちゃうれしい!!ですけど、現状は開発中で使い物にならないんです。。申し訳ないです。。😭 https://t.co/pqJBk8vLfN
— まつけん (@_matken) 2021年2月10日
そもそもC/C++でパッケージマネージャそんな使われてるの?
あまりないように見えるんですよね。
Ruby on RailsのGPL汚染まとめ(mimemagicの件)
("汚染"という言葉をあまり良く思わない方もいると後から知りました。たしかにその通りだと思います。次から気を付けようと思いますが、とりあえず本記事ではそのまま"汚染"の表現を使います。ご了承ください。)
2021年の3月、突如としてRailsのGPL汚染の話題がネット上を駆け巡りました。
リチャードストールマンがFSFへの復帰を発表した途端にこんなことが起きるなんて…。 偶然にしてはすごいタイミングですね。
GitHub Enterpriseのコードが公開されるの?と盛り上がっておりますが、果たしてどうなりますでしょうか。
さて今回は本件についてまとめていきます。技術者だけでなく法務や知財の目線でも分かるように書いていこうかと思います。
★私は法律の専門家ではありません。この記事に法的根拠はありませんので何かあっても責任は取れません。ご理解ください。
概要(経緯)
概要はこのissueのやりとりを見ると良いでしょうか。
RailsではmimemagicというOSS(gemパッケージ)が使われているんですが、本gemにGPLのコードが混ざっていたというのが今回の話になります。 ※正確には、Rails→activestorage→mimemagicの順で依存しているようです。
mimemagicはMIME Typeを識別するライブラリ(MITライセンス)なんですが、MIME Typeの定義情報(xml)を持っており、これがshared-mime-infoという別OSSのxml(ライセンスがGPL)だったようです。
mimemagicの開発者はissueでこの指摘を受け、ライセンスをMIT→GPLに変更(バージョンアップ)し、その後rubygems.org(gemを公開しているところ)で過去バージョンをyanked(公開停止)した上で、最新版を公開した模様。
これにより、mimemagicに依存していたプロジェクトのCI(要はビルド)が軒並み崩壊&さまざまなプロジェクトで影響が出た、というのが今回の件の大まかな流れです。
で、影響を受けたプロジェクトの一つがRailsで「え、RailsってGPLになるの?」「Rails使ってるGitHub Enterpriseどうなるの?」といった話が各所で出ることになりました。
ただし最新状況(3/25の夜の時点)としては、mimemagicの開発者は該当のxmlを取り除いてMITライセンスに戻した最新版を公開しているようです。
【追記】さらに最新状況(3/27時点)としては、Railsの新しいバージョン5.2.5/6.0.3.6/6.1.3.1ではmimemagicに依存しなくなりました。
事実確認
念のため実物を見ていきます。元ネタであるshared-mime-infoの該当ファイル(と思われるファイル)がこちら。たしかにGPLで間違いなさそうです。 https://gitlab.freedesktop.org/xdg/shared-mime-info/-/blob/master/data/freedesktop.org.xml.in#L63-79
次に、これが本当にmimemagicで使われているか、mimemagicのリポジトリを見てみます。最新版ではfreedesktopのファイルが削除されたようなので、過去の履歴から確認してみます。script/freedesktop.org.xml が該当ファイルのようで、たしかに思いっきりGPLと書かれています。
https://github.com/mimemagicrb/mimemagic/blob/40dd02bb6b442535f97c35326c0383bc67146ac4/script/freedesktop.org.xml#L63-L79
あと、このxmlが本当にgemパッケージ(ビルド成果物として実際使われるモジュール)で使われるのか確認してみます。
40dd02bb6bをパッと見た感じ、
script/freedesktop.org.xmlを基にlib/mimemagic/tables.rbを生成する
という流れになっているように見える。xml自体はgemには含まれないようですね。(たぶん合ってるけど間違ってたら指摘してください)
念のためrubygems.orgを見てみるかーと思ったけど過去ver.は公開されていないため実物は確認できず。wayback machineでもgem取れないので諦め。まぁいいか。
とりあえず結論としては、「GPLのxmlそのものはgemに含まれないっぽい」「xmlを基に生成したrubyファイルがgemに含まれる」ような形であることが分かった。
GPL汚染かどうか
ネット上を見ていると「RailsがGPLになっちゃうのか」「RailsはGPLのライブラリを読み込んでいるだけだから影響ないでしょ?」といった意見が散見されます。 これらについて少し補足します。
まず、Railsのコード自体はMITライセンスのままで問題ありません。ですが、「Railsおよびその依存関係コードを含む作品全体」はGPLでライセンスしなければいけない可能性があります。
この作品にはmimemagic(GPL)が含まれていて、GPLには「作品全体にGPLを適用すること」という条件があるからです。
なので、Railsとしては自身のMITライセンスを変える必要はないが、Railsを使って何か作っているプロジェクトに影響が出てしまう=Railsメンテナ側としても放置できない という状態です。
また「そもそもRailsには影響ないでしょ?」の意見についてですが、これは「作品」の定義次第となります。
一般的に作品の定義としては「リンクしたものを一つの作品とする」のが定説になっているかと思います。
これに対して、今回は「Railsがgemパッケージを読み込んでいる」状態であり、これをGPLがどう捉えるか?が問題になります。
まぁおそらくRailsを使って作ったWEBアプリケーションは一つの作品として扱われるのだと思いますが、こればかりは何とも言えません。
また、今回少し特殊なのが、対象がGPLのxmlであること。また、頒布されるのがxmlから出力したrubyのコードであることです。
この感じだとかなり詳しい人に判断を委ねることになると思います。
企業だと通常は安全側に倒すので、この類のものもGPL汚染として考えるのが普通ではないかなと思います。あくまで思うだけですが。
なお、GPL汚染かどうかの判断にはGPLのFAQが使えるので参照ください。ただ今回のパターンについては良い例はない気はします。
【追記】そもそも論としてxmlの著作物性に関する議論もありました。 freedesktop.org.xmlの著作物性 - 西尾泰和のScrapbox
じゃあ、うちのRailsアプリもGPL汚染なの?
これについては、「もしそのRailsアプリを外部に提供するなら」GPLを適用する必要が出てきます。
例えば、Railsを使って作ったサーバ製品(mimemagicを含む製品)を販売するような場合が該当します。
典型的な例としては、GitHub Enterprise(オンプレ版)が該当すると思われます(だからみんな騒いでる)。
逆に、クラウドサービスのように自社にサーバをホストしてサービスとして使う分には基本的にこのような問題はありません。
GPLはライブラリの再頒布(利用)の際の条件なので、再頒布せずに自社のサーバ上で動かすだけなら問題ないです。
ただしAGPLなど、サーバ側で動かすだけでも影響が出てくるライセンスもありますので、ライセンスのチェックはどんなプロジェクトにおいてもちゃんと実施する必要はあります。
でもmimemagicの最新版は完全にMITライセンスなんだよね?
そうです。なので、Railsがmimemagicの最新版を読み込むようになれば、「Railsの最新版は」使っても特に問題なしとなります。
ただ問題なのは、これまでRailsがmimemagic(GPL含む)に依存してしまっていたことです。つまり、これまでRailsを使ってWEBアプリ製品を作って売ってきた企業には影響が出ます。
例えばGitHub Enterpriseであれば、過去にオンプレミス版を売ってきた顧客にはこれまでのGitHub Enterpriseのバージョンに対応するソースコードは開示の義務が発生します。
実質的にGHEのオープンソース化と言えてしまうかもしれません。
ミスってGPL混入させたのはmimemagicなのに、GitHub可哀そうでは?
そうでもないと思います。
これも最終的には専門家が判断することですけど、基本的にOSSは何の責任も保証もなく公開されています。
あらゆる責任はOSSを使う側にありますから、今回の件でOSS側が悪いというのは無理があります。
OSSの中身をちゃんと調べなかった、利用側の責任です。
こういった責任があるので、世の中にはOSSのライセンスをチェックするツールがたくさんあります。
GitHubだってlicensedっていうOSSのライセンスをチェックするツールを公開しています。自分たちでも使っているようなので、その辺はしっかり対策していたはずです。
ただ今回の場合はgemの中身までライセンスチェックしないといけないので、licensedなどの単純なライセンスチェックツールでは把握は難しかったろうと思います。
おそらくFOSSAのようなクラウドサービスを使ってコードレベルのライセンスチェックをしておく必要があったのだろうと思います。
対応策
以上が今回の件についての話になります。
とりあえずはRailsコミュニティやGitHub社の動きを待ってから対応を考えるべきと思いますが、仮にGPL汚染だという判断になった場合に、やった方が良さそうなことを書いておきます。
まず、GPLを使うのがダメなプロジェクト/会社/組織である場合には、mimemagicがどこで使われているか把握する必要があるかと思います。
mimemagicに依存するのはRailsだけではないので「mimemagicに依存するライブラリに依存するプロジェクト」も要把握となります。
mimemagicの被依存性に関する確認はrubygems.orgのreverse_dependenciesを見たり、libraries.ioを見たりすれば良いと思います。
(でも特定バージョンの被依存性の確認はできないっぽい…すんません…)
どうにかして把握したら、まずそれらについてはmimemagicの最新版が適用されるようにします。Railsも早いうちに対応版がリリースされると思いますので、そしたら最新にすべきでしょう。
で、問題はすでにリリースされてしまっているものですね。これについては… どうなるんでしょうね。本当にGPL適用なのかなww やばい企業相当出てくると思うんだけど…。
やるとなったら、まぁ、製品はGPL適用&必要に応じてソースコード提供、ということになるのでしょうね。
まぁでもこれはやはり今後の動きを見てからの判断になるかと思います。
短期的な対応としてはこんなもんでしょうか。
長期的にはやはりCI/CDの流れでFOSSAなどを使って、常時ライセンスをチェックする仕組みを構築すべきと思われます。
また事後対応でも良いという場合にはSourceGraphなどの導入して、いつでも社内のソースコードを検索できるようにしておくと良いかもしれません。
まとめ
途中から法務や知財の目線を忘れて書いてしまいました。すみません。
とりあえず自分の理解を書かせていただきましたが、おかしい点は指摘ください。
また再度言いますが、私は法律の専門家ではないので、何の責任も取れませんのでよろしくお願いします。